Recoverability Simulation Engine
RSE — Runbook Review
Exploring how recovery behaviour changes as conditions deteriorate
Most operational recovery plans are written as if recovery unfolds in a relatively stable environment. They describe escalation paths, timelines, actions, ownership structures, and communication flows, often in considerable detail. But they usually reveal far less about what recovery actually depends on once conditions begin to deteriorate around the organisation.
A plan may appear coherent on paper. The sequencing may look sensible. The escalation paths may be clearly defined. Yet recoverability is rarely determined by whether a process exists in documentation alone. It is often shaped by whether the conditions the process quietly assumes remain true while the organisation is under pressure.
That was the starting point for a new capability within RSE — the Recoverability Simulation Engine.
Rather than treating runbooks as static operational artefacts, I wanted to explore whether they could instead be interpreted as behavioural recovery models. Not simply descriptions of what teams intend to do, but models of how recovery behaviour unfolds under uncertainty, coordination strain, degraded visibility, and narrowing operational trust.
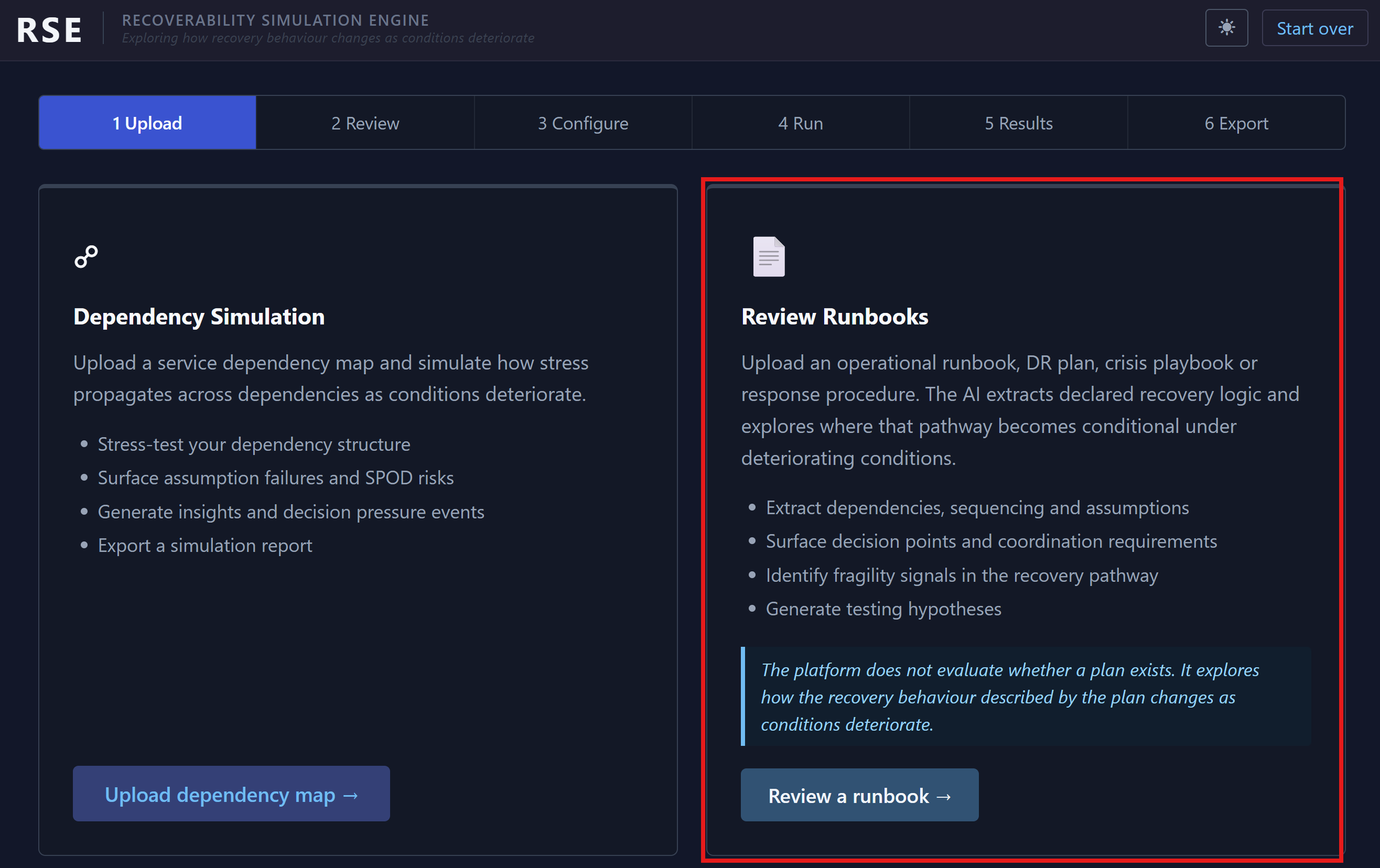
RSE separates behavioural runbook analysis from dependency simulation and condition exploration.
The platform itself is structured around two related but distinct ideas.
The first focuses on analysing the recovery behaviour described inside operational documentation. The second focuses on exploring how dependencies and operational conditions interact dynamically under stress. Although closely related, they solve slightly different problems.
Runbook Review became the first capability I wanted to explore publicly because it raises an interesting question:
What happens when recovery plans are treated less as static documentation and more as behavioural recovery models?
That distinction quickly changes the type of analysis being performed.
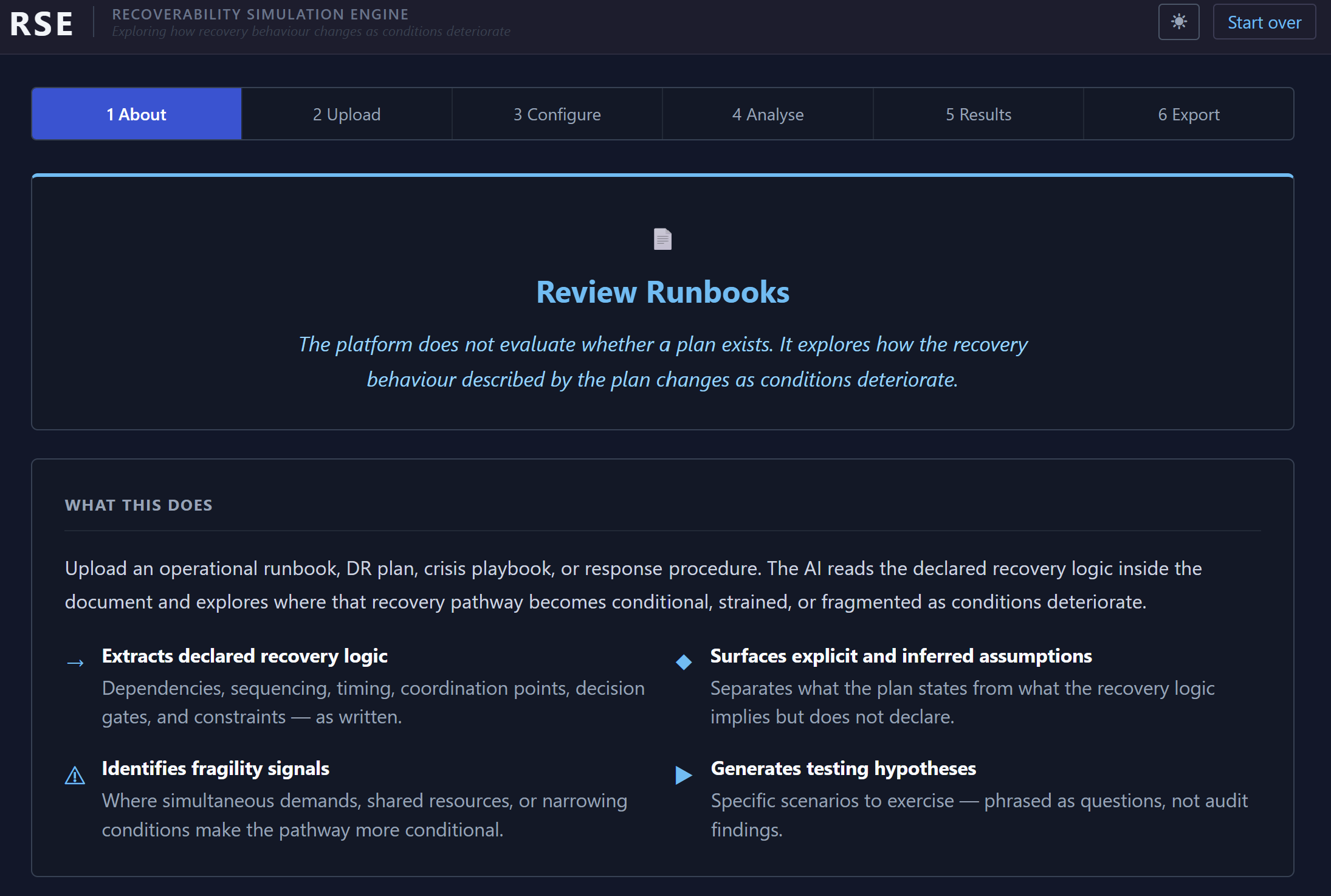
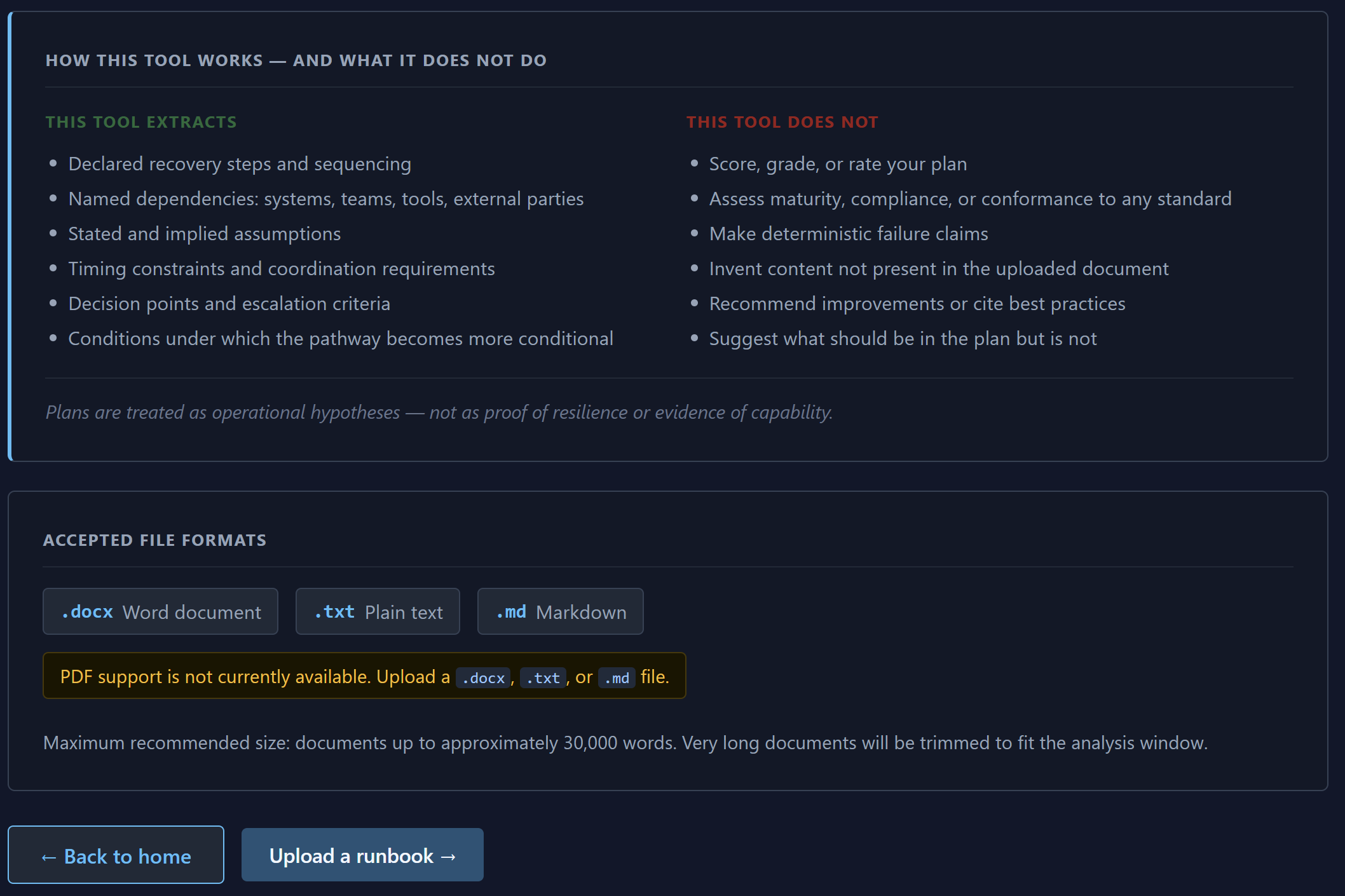
The platform does not attempt to determine whether a plan is “good.” It does not score maturity, assess compliance, or attempt to produce automated resilience ratings. Instead, it explores how the recovery behaviour described by the plan changes as conditions deteriorate.
The central question became:
What happens to recoverability when coordination, visibility, timing, trust, or assumptions begin to fragment under pressure?
The platform focuses on recovery behaviour and conditionality rather than plan quality assessment.
That philosophy became important very quickly during development because it would have been extremely easy for the platform to drift into generic “AI plan review” territory.
That was never the intention.
The more interesting problem was understanding how recoverability itself becomes conditional as operational strain increases.
A plan may contain:
escalation paths,
technical procedures,
communications structures,
mitigation sequences,
and recovery timelines.
But underneath those sequences sit a large number of hidden operational assumptions.
For example:
that monitoring remains trustworthy,
that escalation bridges remain coherent,
that reporting cadence does not collapse under parallel activity,
that key decision-makers remain available,
or that outsourcer visibility remains aligned with internal operational reality.
These assumptions are often carrying substantial parts of the recovery pathway even when they are never explicitly documented.
Runbooks are treated as behavioural recovery models rather than static operational artefacts.
The platform ingests operational runbooks, DR plans, incident procedures, and crisis playbooks before extracting the declared recovery behaviour inside them.
What became increasingly interesting during testing was not simply which dependencies existed, but how recovery behaviour changed once those dependencies became uncertain.
The platform extracts both explicit and inferred dependencies from the operational logic contained within the document. Some are obvious: outsourcers, communications channels, monitoring systems, escalation pathways, reporting structures, identity systems, or recovery tooling.
Others emerge indirectly through sequencing assumptions and coordination behaviour.
Several test playbooks, for example, implicitly assumed that a Crisis Lead would always be immediately available and capable of coordinating parallel workstreams under pressure. Others assumed that internal monitoring remained trustworthy throughout the recovery process, or that escalation quality would remain stable even while visibility was fragmenting.
The more fragmented or incomplete the documentation became, the more interesting the behavioural outputs often were.
A ransomware playbook surfaced strong signals around:
containment-before-certainty,
verification pressure,
parallel workstream overload,
and recovery trust degradation.
A partially unfinished supply-chain compromise procedure still generated meaningful recoverability signals around:
coordination improvisation,
undefined sequencing,
fragmented ownership,
and dependency trust uncertainty.
Interestingly, the platform remained useful even when the documentation itself became operationally messy.
Context and operational framing influence how recoverability conditions are explored.
The configuration layer allows additional operational framing to be introduced before analysis begins. This is intentionally lightweight.
The platform is not attempting to force catastrophic scenarios into the recovery model or artificially inject “severe but plausible” narratives into the process. Instead, the objective is to provide enough operational context for the platform to explore how recovery behaviour changes as conditions begin deteriorating around the documented pathway.
That distinction matters because severity rarely arrives cleanly.
In many operational disruptions:
systems continue functioning,
communication channels remain partially available,
mitigation appears initially effective,
and recovery technically remains possible.
Yet recoverability may already be narrowing underneath the surface because coordination coherence, visibility confidence, sequencing stability, or operational trust have begun degrading simultaneously.
The platform naturally started surfacing these moments of conditionality.
Not simply:
“what the plan says”
but:
“what the recovery pathway quietly depends on.”
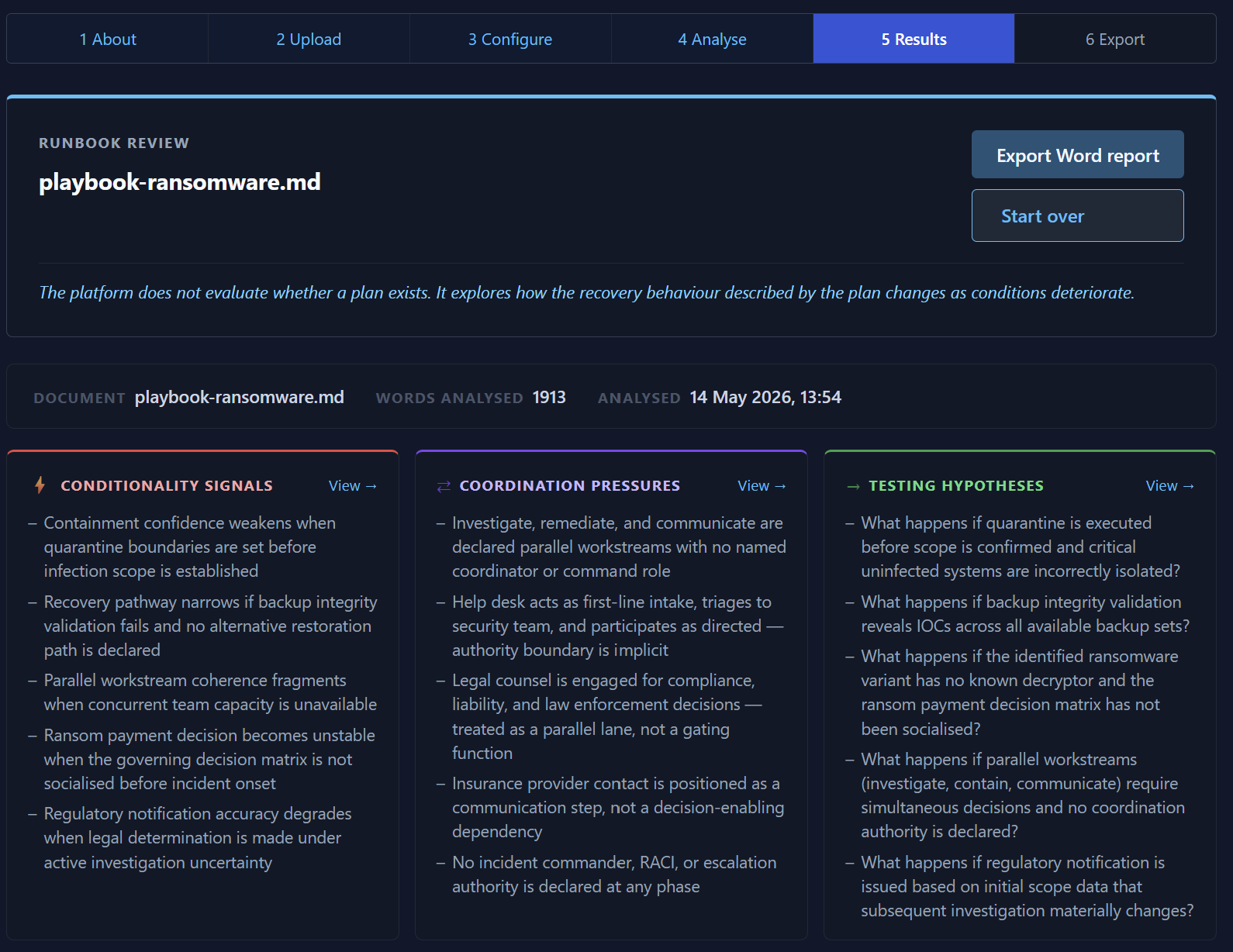
The platform analyses recovery sequencing, assumptions, dependencies, and coordination pressures.
One of the more interesting discoveries during development was that the platform increasingly drifted toward something closer to recoverability coherence analysis.
Not simply asking:
“Can recovery happen?”
But asking:
“Can recovery remain coordinated, trusted, and operationally coherent as uncertainty increases?”
That distinction feels increasingly important because many operational disruptions do not fail cleanly. Systems often continue functioning while visibility weakens, assumptions diverge, reporting coherence degrades, or operational trust narrows around the recovery process itself.
Recoverability often becomes conditional long before outright failure occurs.
This is also why the platform deliberately avoids producing traditional “findings.” It does not tell organisations that their plans are weak, incomplete, or non-compliant. Avoiding that drift became an important design constraint throughout development.
Instead, the platform surfaces behavioural recoverability signals.
Signals such as:
recovery confidence weakening when verification pathways remain incomplete,
coordination coherence narrowing during parallel escalation activity,
visibility diverging between internal monitoring and actual client experience,
or remediation becoming increasingly dependent on responder adaptation rather than declared sequencing.
The language matters here.
There is a meaningful difference between saying:
“the plan is poor”
and saying:
“recoverability becomes conditional once these assumptions stop holding simultaneously.”
The latter is far closer to the operational reality most organisations actually face during sustained disruption.
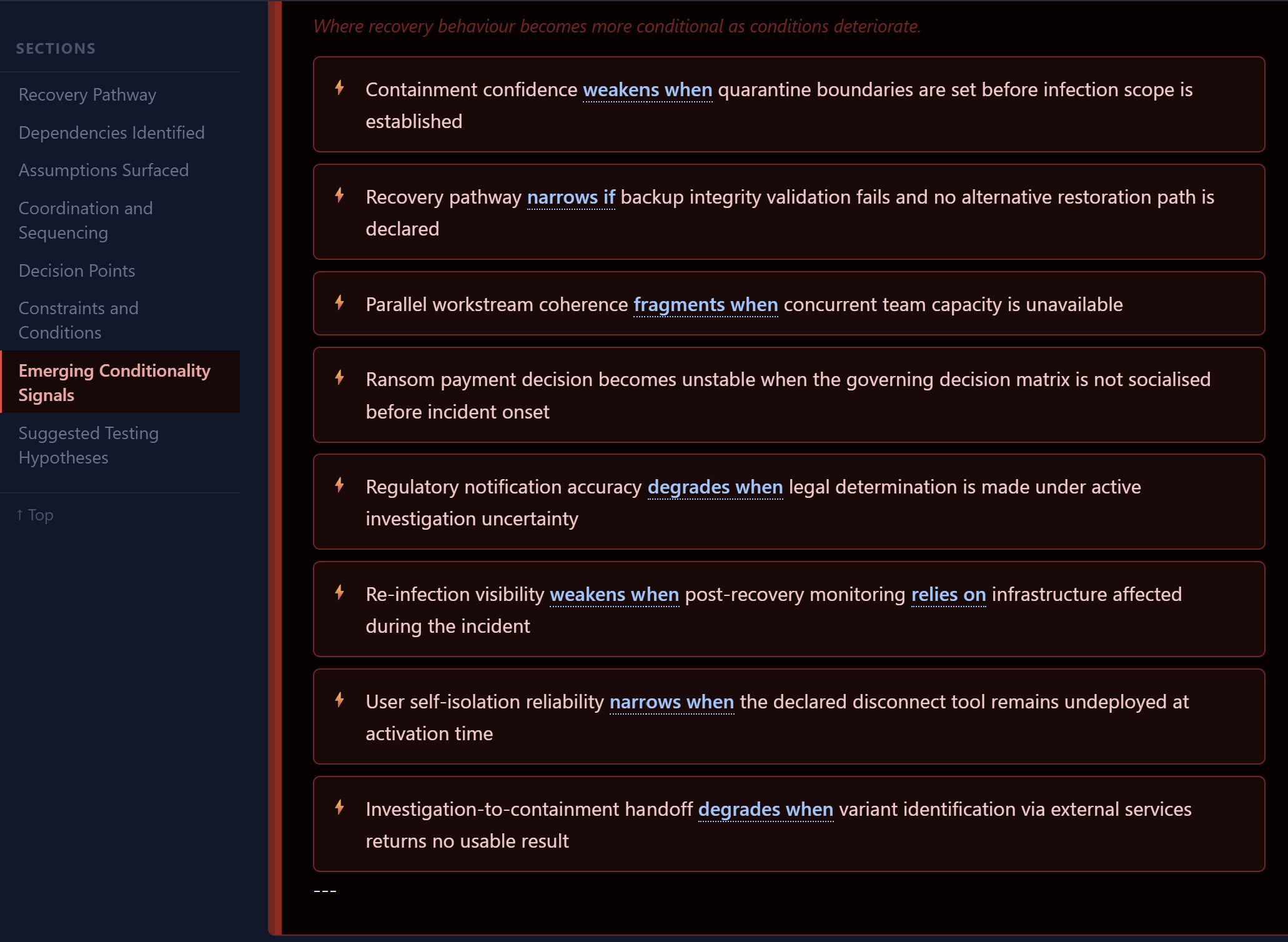
Emerging conditionality signals surfaced from operational recovery logic.
The results layer became the most conceptually interesting part of the platform.
Rather than producing static summaries, the analysis increasingly began surfacing:
narrowing recovery pathways,
coordination strain,
dependency concentration,
verification pressure,
sequencing instability,
and confidence degradation within the recovery process itself.
What surprised me most was how often the most interesting outputs emerged from ambiguity rather than clarity.
Highly structured playbooks produced coherent analysis, but fragmented or partially unfinished operational procedures often surfaced the richest behavioural signals because they exposed where recoverability quietly depended on adaptation, improvisation, or undeclared coordination assumptions.
In many cases, the recovery pathway technically still existed.
But confidence in the pathway had already started eroding long before anyone would formally declare the recovery process a failure.
The results can be exported — you can download a copy of the export here - DOWNLOAD THE EXPORTED DOCUMENT
At this stage, Runbook Review represents only one layer of the broader RSE concept. The more interesting direction may eventually involve exploring how multiple recovery pathways interact simultaneously across dependencies, third parties, identity systems, operational teams, communications structures, and deteriorating operational conditions.
That is where the wider simulation and dependency capabilities inside RSE begin to matter.
Even in its current form, however, the platform already appears to reveal something important:
Recoverability is often far more conditional than operational documentation suggests.
The most interesting part was not whether the plans existed.
It was how quickly recovery became dependent on assumptions that were rarely visible until coordination fragmented, visibility weakened, or operational trust began narrowing under pressure.
Authors Note:
Over time, I expect parts of RSE will become more openly available so others can explore these ideas in their own environments.